
본격적인 데이터 분석 첫 시작!
12주 차 강의 첫 번째 날에는 본격적으로 데이터 분석에 필요한 학습이 진행되었다.
데이터 분석이 무엇인지 알기 전에, 우선 데이터란 무엇인지 알아보자.
"데이터란 현실 세계의 일들을 관찰, 측정해서 얻은 값을 말하고 그러한 데이터를 처리해서 얻은 의미 있는 값을 정보라고 한다. 그리고 데이터 분석은 데이터를 활용하여 원하는 정보를 얻어내기 위한 일련의 과정이다."
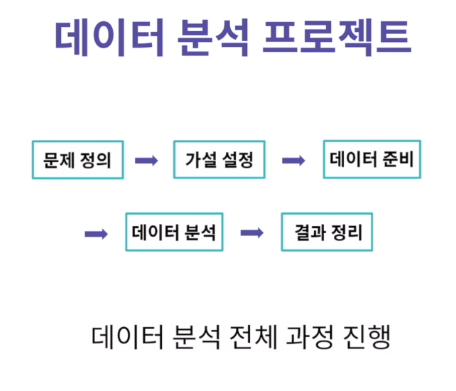
데이터 분석 프로젝트는 데이터 분석을 위해 일련의 과정을 진행하는 것을 의미한다.
그 전체적인 과정은 다음과 같다.
1. 문제 정의: 현재 풀고자 하는 문제가 무엇인지를 명확히 정의
2. 가설 설정: 문제를 해결하기 위한 데이터 분석의 토대인 가설 설정
3. 데이터 준비: 풀고 싶은 문제에 대한 정보를 담고 있는 데이터셋을 설정
4. 데이터 분석: 본격적인 데이터 분석(프로젝트의 성공 여부는 데이터 이해의 정도성에 따라 좌우된다.)
5. 결과 정리: 분석 과정에서 알아낸 인사이트(insight) 정리 단계
다음으로 데이터 분석 프로젝트 진행을 위해 환경 설정을 해줬는데 Jupyter Notebook을 활용했다.
Jupyter Notebook 이란?

웹 브라우저에서 코드를 작성하고 실행해볼 수 있는 오픈 소스 소프트웨어이다.
주피터 노트북을 활용하여 위에서 살펴본 전체 과정을 진행할 수 있다.
주피터 노트북은 아나콘다 설치 시 자동으로 설치가 된다.
Anaconda | Individual Edition
Anaconda's open-source Individual Edition is the easiest way to perform Python/R data science and machine learning on a single machine.
www.anaconda.com
(다운로드는 여기서)
주피터 노트북의 장점으로는 셀 단위 코드 실행이 가능하다는 것이다. 따라서 실시간으로 결과를 확인해야 하는 데이터 분석이나 머신 러닝과 같은 프로젝트를 수행할 때, 매우 용이하게 사용 가능하다.
우선 주피터를 실행하면 다음과 같은 프롬프트 창이 뜬다

그리고 자동으로 브라우저에서 주피터 노트북 창이 실행된다.

그리고 이번 주에는 주피터의 응용뿐 아니라 문서를 깔끔하고 편리하게 만들어주는 언어인 마크다운(Markdown)에 대해서도 배웠다.
대부분의 개발 문서(주피터의 셀 포함)에서 활용되는 언어이기 때문에 한 번쯤 배워 놓으면 좋겠다고 생각했다.

마크 다운의 간단한 문법은 다음과 같다.
가장 큰 제목 (H1)
- 맨 앞에 # 하나 붙이기
(#의 개수가 4일 때까지 H1에서 H4순으로 크기가 점점 작아진다.)
하지만 #의 개수가 5일 때는 H5가 아니라
- 기울어진 볼드체가 작성된다.
구분선 만들기
- ---(dash 세 개)
리스트 만들기
- -(dash 한 개, tab 하면 들여쓰기가 적용된다.)
인용문구
- '>' 문자를 맨 앞에 붙여준다.
코드 감싸기
- 한 줄 짜리 코드를 감쌀 때는 `(backtick 한 개)으로 감싸고
- 코드의 줄이 여러 줄 일 때는 ```(backtick 세 개)을 코드의 시작과 끝에 각각 붙여준다.
줄 바꿈
(깃의 readme파일을 처음 작성할 때 개행이 내 맘대로 안돼서 애를 먹은 기억이 있어서 개인적으로 잘 알아놔야 할 문법이 아닐까 생각...)
- 마크다운에서 개행은 한 줄의 마지막에 세 칸 이상 띄어쓰기를 해야한다. (아무리 엔터를 많이 쳐도 개행 안됨)
- 만약 빈 줄을 넣고 싶으면 html 문법과 같이 <br>을 작성하면 된다.
본격적인 데이터 분석 실습
첫째 날에 설정한 개발 환경(Jupyter Notebook)으로 두 가지의 데이터 프로젝트를 진행하였다.
첫 번째는 국내 코로나 환자 데이터 분석, 두 번째는 지하철 승하차 인원 정보를 활용한 역별 혼잡도 분석이다.
두 개의 데이터 프로젝트 모두 다음과 같이 동일한 순서로 진행되었다.
1. 데이터 읽기: 주어진 데이터를 불러오고 DataFrame 구조를 확인
2. 데이터 정제: 데이터 확인 후 이상치 데이터 처리
3. 데이터 시각화: 각 변수별로 추가적인 정제 또는 feature engineering 과정을 거치고 시각화를 총해 데이터 특성 파악
데이터를 불러올 때 사용한 패키지 및 라이브러리는 다음과 같다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
데이터는 info 함수를 통해 dataframe의 요약된 형태로 출력하였다.

데이터를 간략히 확인하였으므로 다음은 데이터 정제를 통해 이상치의 값들을 처리하였다.
우선 위에서 나온 info 함수의 출력을 보면 국적, 환자정보, 조치사항 칼럼에는 데이터가 존재하지 않기 때문에
이것들을 drop() 함수를 사용하여 삭제하는 작업을 진행하였다.
# drop 함수를 사용하여 국적, 환자정보, 조치사항 coulmn 데이터를 삭제합니다.
corona_del_col = corona_all.drop(columns = ['국적','환자정보','조치사항'])

마지막으로는 월별 확진자 수를 출력하는 데이터 시각화를 진행하였다.
시각화를 진행하기 앞서 우선 문자열 형식인 월, 일 데이터를 숫자 형 데이터로 변화시키는 전처리 과정(preprocessing)을 수행했다.
# dataframe에 추가하기 전, 임시로 데이터를 저장해 둘 list를 선언
month = []
day = []
for data in corona_del_col['확진일']:
# split 함수를 사용하여 월, 일을 나누어 list에 저장
month.append(data.split('.')[0])
day.append(data.split('.')[1])
# corona_del_col에 `month`, `day` column을 생성하며 동시에 list에 임시 저장된 데이터를 입력
corona_del_col['month'] = month
corona_del_col['day'] = day
# 문자열 데이터가 저장된 month, day 컬럼을 int64 형태로 변경
corona_del_col['month'].astype('int64')
corona_del_col['day'].astype('int64')
마지막으로는 위 과정에서 처리된 month 칼럼의 데이터를 바탕으로 월별 확진 수를 막대그래프로 출력하였다.
과정은 우선 order라는 변수를 생성해 x축의 순서를 정의하였고, 이 정의된 순서를 바탕으로 seaborn의 countplot 함수를 이용하여 출력하였다.
# 그래프에서 x축의 순서를 정리하기 위하여 order list를 생성
order = []
for i in range(1,11):
order.append(str(i))
# 그래프의 사이즈를 조절
plt.figure(figsize=(10,5))
# seaborn의 countplot 함수를 사용하여 출력
sns.set(style="darkgrid")
ax = sns.countplot(x="month", data=corona_del_col, palette="Set2", order = order)
출력 결과:

전문가에게 배우는 데이터 분석 이론 및 실습
이론 수업의 진행 순서는 다음과 같았다.

이론 수업의 초반은 코치님에게 레이서 분들이 데이터 분석에서 많이 질문을 한 것들 위주를 답해주는 형식으로 진행하셨다.
그리고 어떤 분이 채팅창에

이렇게 질문하셨는데 코치님이 못 보고 지나쳐서 ㅋㅋㅋ 나름 혼자 찾아봤는데
현업에서는 보통 수정이 필요한 데이터 인덱스의 이름을 통해 명시적으로 인덱싱이 가능한 loc가 iloc 보다 더 많이 쓰인다고 한다.
이론 시간이 끝나고 실습 시간에는 DataFrame으로 sql을 사용할 수 있는 라이브러리인 pandasql을 알려주셨다.

(주피터 노트북은 sql 쿼리문 연습하기에도 좋을 것 같다.)
실습강의에서는 코치님께서 저번에 내주신 퀴즈를 맞춰보고 풀이하는데 중점을 두었다. 그리고 수업을 진행하면서 다양한 꿀팁들을 알려주셨다.
난 여태 어떠한 데이터 셋의 정보를 출력할 때, 사용할 수 있는 함수는 info() 밖에 몰랐는데 오늘 코치님이 데이터의 상세정보를 출력하는 describe() 함수 사용법을 알려주셨다.

위와 같이 데이터의 숫자형 칼럼의 분포의 특성을 간략하게 출력해준다.
그리고 한 칼럼에 두 개 이상의 데이터가 존재할 때, 각각의 데이터를 간략하게 출력하는 value_counts() 함수도 배웠다.

나는 칼럼의 각 값의 길이를 변환해서, 보기에도 길고 복잡하게 계산했는데...
value_counts()라는 함수를 쓰면 딱 한 줄로 편리하게 칼럼의 각 데이터의 개수를 간략하게 출력해준다. ㅎ
또 배웠던 것 중에 신기했던 건 데이터 셋의 칼럼을 가리킬 때 반드시 "데이터['칼럼명']"의 형식을 따르지 않고, "데이터. 칼럼명"의 형식을 써도 된다는 것이다.
# 1/age의 제곱근(분자:1, 분모:age의 제곱근)에 해당하는 값을 child_df의 age_weight 이라는 열로 추가 (lambda와 apply 사용. 제곱근의 경우 numpy를 이용해 구할 수 있음)
# child_df['age_weight'] = 1/(np.sqrt(child_df['age']))
child_df['age_weight'] = child_df.age.apply(lambda x: 1/np.sqrt(x))
# 추가한 후 child_df의 앞의 5개행만 확인
child_df.head()
위의 코드에서 child_df.age.apply()라는 코드에서 원래는 child_df ['age']이런 형태로 작성했는데,
굳이 괄호를 쓰지 않고 "."으로 구분을 주면 더 간단하게 표현이 가능하고 똑같은 값을 얻을 수 있다.
데이터 분석에서 유용한 메서드들
상위 데이터 5개를 출력해주는 head() 함수의 반대인 하위 데이터 5개를 뽑아주는 tail() 함수를 배웠다.
# 하위 5개 데이터를 출력합니다.
df.tail()
또한 데이터의 결측치라는 것을 배웠는데, 결측치란 빈 데이터를 말한다.
결측치는 isna() 함수를 사용하여 확인할 수 있다.
# 각 열 별로 결측치의 갯수를 반환합니다. (True:1, False:0)
df.isna().sum()
엘리스 수업에서 결측치의 개수를 확인할 때 위와 같이 sum() 함수를 사용했지만 또 다른 방법으론 value_counts() 함수를 사용하는 방법이다.
df.isna().value_counts()
그리고 결측치가 있는 행을 만약 내가 삭제하고 싶으면 dropna() 함수를 사용하면 된다.
df.dropna()
또는 결측치가 존재하는 열 자체를 제거하고 싶으면 데이터의 방향을 나타내는 'axis'를 이용하여 삭제시켜주면 된다.
df.dropna(axis = 1)(axis가 0이면 행(가로) 방향, 1이면 열(세로) 방향)
12주 차 학습을 통해
12주 차는 본격적인 데이터 분석의 실습이 시작된 주였다. 정말 한 주 동안 데이터 분석에 관한 무수한 메서드들의 사용법과 코치님들에게 꿀팁을 전수받았지만... 아직 모르는 것 투성이다. 나름 열심히 정리도 하려고 하지만 막대한 양에 살짝 힘든 감이 없지 않다. 그래도 13주 차 지나 그다음 주부터 시작되는 팀 프로젝트에서 팀에 도움은 못 줄 망정 폐 끼치는 팀원은 되기 싫기 때문에 NIPA 데이터 분석 교육과 병행하면서 더 열심히 공부해야겠다고 느낀 한 주다.
'Challenge > 엘리스 AI 트랙 2기' 카테고리의 다른 글
| 엘리스 AI 트랙 2기 - 16, 17주차 모히또 레이서의 학습일지 (2) | 2021.10.23 |
|---|---|
| 엘리스 AI 트랙 2기 - 14, 15주차 모히또 레이서의 학습일지 (1) | 2021.10.23 |
| 엘리스 AI 트랙 - flask를 이용한 개인 프로젝트 (1) | 2021.09.13 |
| 엘리스 AI 트랙 2기 - 13주차 모히또 레이서의 학습일지 (1) | 2021.09.13 |
| 엘리스 AI 트랙 2기 신청부터 ~ 합격까지 (19) | 2021.07.07 |



